Recombinative evolution will outperform local search on fitness functions that have a property called deep contingency. In this blog post I will:
- Present a fitness function possessing the property in question and empirically show that a genetic algorithm handily outperforms simulated annealing.
- Argue that the presented problem is a difficult one, and the non-trivial computation performed by the genetic algorithm is just what’s needed.
- Explain why simulated annealing, and indeed, local search of any kind, is the wrong way to approach the problem presented.
This is going to be a lengthy post, and you are welcome to jump to the punch. First, I want to explain why it has taken till now to procure a whitebox optimization problem on which a genetic algorithm outperforms simulated annealing. The short story is that we did not, till recently, have good theories about the computational power of recombinative evolution.
Here’s the long story:
Logical Positivism vs the Scientific Method in Genetic Algorithmics
The genetic algorithm owes its form to biomimicry, not derivation from first principles. So, unlike the workings of conventional optimization algorithms, which are typically apparent from the underlying mathematical derivations, the workings of the genetic algorithm require elucidation. Attempts to explain how genetic algorithms work can be divided in two: those based to a lesser or greater extent on the scientific method, and those that reject the scientific method in favor of logical positivism.
Positivism is the idea that the only true knowledge is knowledge that can be verified. Logical postivism is the idea that verification can be carried out through the application of formal logic to empirical observations. Logical Positivism originated in the first quarter of the twentieth century and was explored and popularized by the Vienna Circle, a group of philosophers, scientists, and mathematicians that met regularly from 1924 to 1936 at the University of Vienna. Buoyed by rapid advances in the axiomatization of mathematics, logical positivists believed that like mathematics, all of science could be derived within a formal axiomatic system where the list of axioms consist of 1) empirical observations, a.k.a. protocol sentences and 2) the axioms of mathematics (e.g. ZFC). The movement to recast science in this mould gained currency in the first quarter of the twentieth century but subsequently came to be regarded as untenable. Writing in 1971, Werner Heisenberg offered this reflection about positivism in general:
The positivists have a simple solution: the world must be divided into that which we can say clearly and the rest, which we had better pass over in silence. But can any one conceive of a more pointless philosophy, seeing that what we can say clearly amounts to next to nothing? If we omitted all that is unclear we would probably be left with completely uninteresting and trivial tautologies. (Heisenberg 1971)
The non-universality of empirical observation was a particularly vexing problem for logical positivism. Given the verificationist foundations of this movement, only empirical observations made at a particular point in time and space were admissible as protocol sentences. Generalization to other points in time and space was not allowed. This made it hard to prove much of value. Proponents of logical positivism tied themselves in knots trying to address this and other critiques. By the mid twentieth century, the logical positivist movement had largely crumbled and the philosophy of science propounded by Karl Popper had gained traction.
While the universality of scientific theories makes logical verification (i.e. proof) difficult, if not impossible, that very universality, observed Popper (2007b, 2007a), makes disproof (i.e. falsification) a much easier path to pursue. All it takes is a single counterexample—that is, a single prediction not borne out—to disprove a theory as it currently stands. Of course a theory must lend itself to falsification in the first place, and Popper cautioned strongly against theories that employed what he called immunizing strategems to avoid falsification. Such theories (Freud’s theory of psychoanalysis for example)
…appeared to be able to explain practically everything that happened within the fields to which they referred. The study of any of them seemed to have the effect of an intellectual conversion or revelation, opening your eyes to a new truth hidden from those not yet initiated. Once your eyes were thus opened you saw confirming instances everywhere: the world was full of verifications of the theory. Whatever happened always confirmed it. Thus its truth appeared manifest and unbelievers were clearly people who did not want to see the manifest truth. (Popper, 2007a, p45)
Scientific theories, in contrast, are theories that take risks. By predicting weird phenomena (e.g. gravitational lensing in the case of Einstein’s theory of general relativity) they leave themselves open to refutation. “A theory which is not refutable by any conceivable event is non-scientific”, wrote Popper. “Irrefutability is not a virtue (as people often think) but a vice” (Popper, 2007a, p46).
Whether day-to-day science, with its tribalism and politicking, actually works as Popper described has been rightly disputed (Kuhn 2012, Latour 1987). However, it is hard to argue with the historical success of the scientific method, or with Popper’s simple and elegant use of contraposition to frame the normative practice of science:

Here is Popper in his own words:
Like many other philosophers, I am at times inclined to classify philosophers as belonging to two main groups—those with whom I disagree, and those who agree with me. I might call them the verificationist or the justificationist philosophers of knowledge or of belief, and the falsificationists or falibilists or critical philosophers of conjectural knowledge …
The members of the first group—the verificationists or justificationists—hold, roughly speaking, that whatever cannot be supported by positive reasons is unworthy of being believed, or even of being taken into serious consideration.
On the other hand, the members of the second group—the falsificationists or falibilists—say, roughly speaking, that what cannot (at present) in principle be overthrown by criticism is (at present) unworthy of being seriously considered; while what can in principle be so overthrown and yet resists all our critical efforts to do so may quite possibly be false, but is at any rate not unworthy of being seriously considered and perhaps even of being believed—though only tentatively. (Popper 2007a)
Popper famously claimed to have “killed positivism”. Were he alive today, he might be intrigued by the resurrection of positivism in at least one corner of Computer Science. Consider the following passage in Vose’s book, The Simple Genetic Algorithm (Vose 1999):
My central purpose in writing this book is to provide an introduction to what is known about the theory of the Simple Genetic Algorithm. The rigor of mathematics is employed so as not to inadvertently repeat myths or recount folklore.
The decision to accept assertions only when proved is not without price. Few (certainly not I) have mastered enough mathematics to make its application trivial. Another cost is that one is forced to trade what is believed to be true for what can be verified. Consequently this account is silent on many questions of interest for lack of proof.
The “myths” and “folklore” mentioned above reference the Building Block Hypothesis, the idea that genetic algorithms work through the hierarchical composition of short chromosomal snippets that confer above average fitness. The inventor of the genetic algorithm, John Holland, hypothesized that this type of hierarchical composition was the reason for the genetic algorithm’s effectiveness on a range of combinatorial optimization problems. Unfortunately, the building block hypothesis and other hierarchical composition hypotheses (Watson 2006) have been propped up long after it has become clear that such hypotheses cannot be reconciled with a long list of theoretical and empirical anomalies.
The obstinacy of the hierarchical compositionalists when confronted with these anomalies resulted in an interesting transition within the theoretical evolutionary computation community. Hypotheses on the whole came to be regarded with wariness and there was a general hardening of resolve to, as Vose put it, “accept assertions only when proved.” For well over a decade now, foundational research on evolutionary computation has had a decidedly positivist bent. The logical positivism practiced by evolutionary computation theorists is a purer version of the logical positivism espoused by the Vienna Circle in that evolutionary computation theorists find no use for empirical observations, and rely exclusively on the axioms of mathematics. The body of work that goes by the name Runtime Analysis is but the latest in a line of positivist evolutionary computation literature stretching back to the 1990s.
Now perhaps this is just as well. Perhaps logical positivism was simply a movement in search of a niche, and perhaps the foundation of evolutionary computation is just that niche. Maybe. But frankly, there is no a priori reason why any of this should be so. I’ll grant that it is possible to verifiably explain the workings of a large number of computer algorithms—for example, the workings of the algorithms in Cormen et al’s classic, Introduction to Algorithms—however, these algorithms were constructed to have verifiable explanations. Explanatory verifiability, in other words, was a design consideration, not a coincidence. The same cannot be said for the genetic algorithm, which, as I said earlier, owes its form to biomimicry.
The fact of the matter is logical positivist approaches have not yielded answers to the kinds of questions that users of evolutionary algorithms care about. Rather, they have diverted research on the foundations of evolutionary computation toward the study of highly simplified—neutered, one might say—algorithms, for example, the (1+1)-EA, and trivial fitness functions, for example, onemax. In 1999, Vose wrote that his positivist account is “silent on many questions of interest for lack of proof.” Wikipedia’s embarrassing entry on Genetic Algorithms suggests that the situation today is no different.
One might ask why the scientific method—an approach that has acquitted itself splendidly in field after field—was so readily cast aside in favor of logical positivism? I think it has to do with evolutionary computation being a subdiscipline of Computer Science, and Computer Science, contrary to its name, not really being a science. By this I mean that unlike the foundations of say Physics, Chemistry, or Biology, the foundations of Computer Science are purely mathematical—hypotheses play no part. So, while Computer Science has seen engineering revolutions aplenty, it has witnessed nothing similar to the transition in Physics from a Newtonian universe to an Einsteinian one, or the move in Chemistry from the phlogiston theory of combustion to Lavoisier’s oxygen based theory, or any of the other paradigm shifts described in Kuhn’s Structure of Scientific Revolutions (2012). Mathematics, of course, figures prominently in the foundations of the natural sciences, however it is always in support or within the rubric of some hypothesis. Theoretical Physicists, Chemists, and Biologists trained informally, if not formally, in the ways of the scientific method know how to evaluate and work with scientific hypotheses. The same cannot be said of lay mathematicians and theoretical computer scientists.
The field of Genetic Algorithms, which was founded on a hypothesis, is quite possibly the first genuinely scientific discipline within Computer Science. Unfortunately, the field has been a poor standard bearer for the use of the scientific method within Computer Science. Whereas a healthy science moves towards increasing levels of vulnerability, a.k.a. falsifiability, hierarchical compositionalists, when confronted with various anomalies, armored up by moving toward unfalsifiability. For example, as criticism of the building block hypothesis mounted, Holland put forth the building block thesis (Holland 2000), an unfalsifiable theory that essentially contends that hierarchical composition is at play in a genetic algorithm because, well, hierarchical composition is at play almost everywhere. When push comes to shove, the refrain “What else might recombination be doing?” is a well worn fallback. In a mature field of science, such maneuvering would immediately be called out for violating the safeguards that are part of the scientific method. In the fledgeling scientific field of evolutionary computation, however, this critique was not leveled. Instead, logical positivism took root and “hypothesis” became a dirty word.
The Missing Royal Road Function
The way forward for foundational genetic algorithms research lies not in doubling down on logical positivism or hierarchical compositionalism, but in scientific rigor which—to reiterate one of the main points of the previous section—is more than mere mathematical rigor. The cornerstone of scientific rigor is the submission of a falsifiable hypothesis based on weak assumptions for review and refutation. Scientific rigor must be continually maintained through a sustained, community-wide effort to make predictions and test them (e.g. the prediction of the Higgs Boson). Anomalies must be spotted and called out. Resolving them should be an urgent matter. Ignoring them should be unacceptable.
Like all search algorithms, genetic algorithms perform optimization by exploiting some structural property of the fitness function to which it is applied. Therefore, any scientific hypothesis about the workings of genetic algorithms must, at a minimum, be comprised of two parts:
- Structural Assumptions: A specification of the structural properties of fitness functions that get exploited by genetic algorithms
- Exploitation Story: A description of how these structural properties are efficiently exploited
Hierarchical compositionalism assumes the existence of multitudes of modules (low order schemata) that individually confer above average fitness. Also assumed is the existence of hierarchical synergy amongst these modules; i.e. the existence of second level modules that confer a higher fitness on average than the combination of the fitness increments conferred by their constituent first level modules; likewise, the existence of third level modules that confer a higher fitness on average than the combination of the fitness increments conferred by their constituent second level modules; and so on. These are the structural assumptions of hierarchical composition hypotheses. Here is the exploitation story: a genetic algorithm preferentially selects individuals with first level modules, then efficiently mixes the first level modules to create individuals with second level modules, then efficiently mixes those individuals to create individuals with third level modules, and so on.
In previous work I have criticized hierarchical compositionalism on the grounds that its structural assumptions are much too strong. (Remember, we are talking about fitness functions arising in practice through the ad hoc representational choices of genetic algorithm users.) Here I want to raise a different problem confronting hierarchical compositionalist: their inability to procure a royal road function in support of hierarchical compositionalism.
The idea behind royal road functions is simple: Given a hypothesis about the workings of genetic algorithms, it should be possible to procure a fitness function such that the following criteria are satisfied:
- The structural assumptions of the hypothesis are met by the fitness function.
- The behavior of a genetic algorithm when applied to the fitness function clearly matches the behavior described in the exploitation story of the hypothesis.
- The genetic algorithm is observed to be more successful at optimization on the fitness function than naive alternate approaches—hill climbing, for example.
A fitness function that meets these criteria is called a royal road function. Trying to find such a function accords well with the scientific method outlined by Popper. Essentially, a hypothesis about the workings of genetic algorithms should predict the existence of one or more royal road functions. Finding such functions validates the prediction and lends credibility to the hypothesis.
A formal review of the literature on royal road functions should at a minimum cover Mitchell et al’s original work on Royal Road functions (Mitchell 1998), Holland’s hyperplane defined functions (Holland 2000), and Watson’s HIFF functions (Watson 2006). Such a review is beyond the scope of this blog post. What I will say here is that hierarchical compositionalists have tried and failed to find a fitness function that satisfies the criteria listed above.
Contingent Parities Functions
I will now present a function that satisfies the royal road criteria. The hypothesis supported by this function has nothing to do with hierarchical compositionalism. Instead the function lends credibility to a different hypothesis about the workings of genetic algorithms called the generative fixation hypothesis (Burjorjee 2009).
A Contingent Parities Function of order k and height h is pseudo-boolean function that takes a bitstring of length k*h as input and returns an integer in the interval [0,h]. The pseudocode for this function appears below:

Given a chromosome of length k*h as input, the fitness of the chromosome, i.e. the output of the contingent parities function, is determined by the parity of the loci in a series of h sets of loci, each of cardinality k. Each set of loci in this series is called a step. Now for the crucial part: For all i in {2, …, h}, observe that the composition of step i is not the same for all chromosomes, but is contingent upon the hash of a trace string comprised of the loci participating in steps 1 to i-1 and the values of the loci comprising these steps.
A chromosome is said to have misstepped at level i if the values of the loci in the ith step have even parity. Otherwise the chromosome is said to have eustepped at level i. The maximum number of missteps a chromosome can have is h. The difference between h and the number of missteps is the fitness of the chromosome (see line 17).
Time for an example. Given some contingent parities function of order 2 and height 8, the table below shows a sorted list of final trace strings and fitness values of thirty chromosomes of length 16 generated uniformly at random.
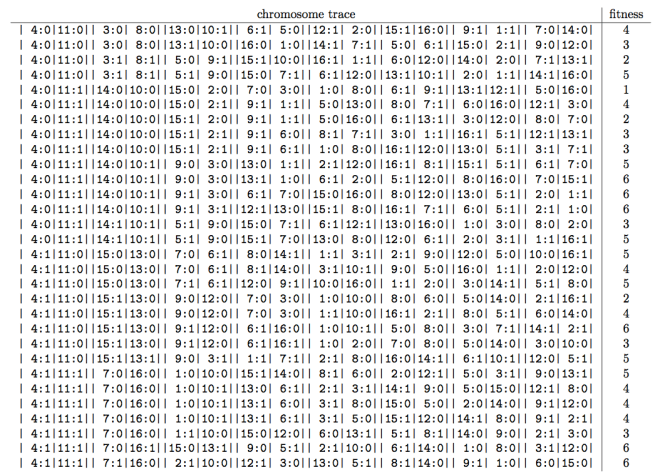
To generate such traces yourself clone the github repository that accompanies this article, and execute the following python code:
import royalroads as rr import numpy.random as npr # generate a contingent parities function of order 2 and height 8 cpf = rr.generateContingentParitiesFunction(order=2, height=8) # generate 30 chromosomes of length 16 uniformly at random chromosomes = npr.rand(30,16) < 0.5 # evaluate the chromosomes cpf(chromosomes, verbose=True)
The challenge, given query access to a contingent parities function, is to find a chromosome that maximizes fitness. There are 2(k-1)*h such chromosomes. Before proceeding further, you should convince yourself a) that this is not a simple problem and b) that local search is not a great way to approach it. Observe, in particular, that the correction of lower level missteps can turn higher level eusteps into missteps; however, the reverse is not true. That is, the correction of higher level missteps cannot turn lower level eusteps into missteps. Thus, the higher the fitness of a chromosome, the less likely it is that local search will successfully correct any low level missteps. In other words the fitness structure of the problem is such that local search will tend to “freeze in” lower level missteps as search proceeds.
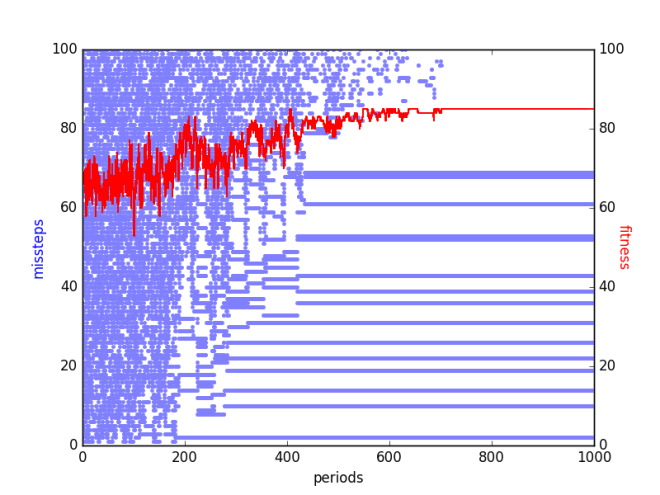
This behavior can be observed in the following figure which shows the missteps of a chromosome with maximal fitness (in blue) every 500 epochs (called a period) when simulated annealing was run on a contingent parities function of order 2 and height 100. The maximal fitness achieved in each period is shown in red. The probability of accepting a solution with a fitness of one less than that of the current solution was 0.6 at the beginning of the run and 0.001 by the end of the run.
 The plot above can be regenerated as follows:
The plot above can be regenerated as follows:
import royalroads as rr rr.SA(rngSeed=1, numPeriods=1000)
The horizontal lines in the plot are missteps that have been frozen in. All in all there are 15 such missteps, resulting in a fitness of 85 by the end of the run.
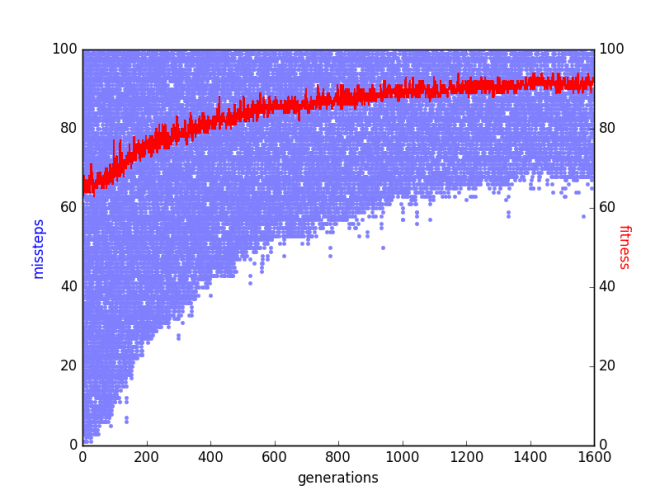
As the correction of higher level missteps cannot turn lower level eusteps into missteps, a methodical way to optimize a contingent parities function is to get lower steps right before getting higher steps right. This is precisely what a genetic algorithm does when applied to the function. A simple genetic algorithm with uniform crossover, fitness proportional selection, sigma truncation (with coefficient 0.5), a per bit mutation probability of 0.004, and a population size 500 was run on the same contingent parities function for 1600 generations. The figure below shows the maximal fitness and the missteps of a chromosome with maximal fitness in each generation.
This plot can be regenerated as follows:
import royalroads as rr rr.GA(rngSeed=1, numGenerations=1600)
The figure shows that the simple genetic algorithm methodically got lower level steps right before it got higher level steps right. That said, diminishing returns soon set in, and there came a point beyond which there was no steady increase in the number of eusteps in the chromosome with maximal fitness. Simple genetic algorithms have been criticized for lacking a “killer instinct”. The results obtained here validate this criticism. The genetic algorithm’s ability to methodically correct missteps peters out even though from a Detection Theory perspective, it is actually easier to correct higher steps than it is to correct lower steps.
I have previously accounted for the absence of a “killer instinct” and have provided a simple fix called clamping (Burjorjee 2009, 2013). I reran the simple genetic algorithm, this time with clamping turned on (a flag frequency threshold of 0.01, an unflag frequency threshold of 0.1 and a waiting period of 60 generations was used). The results appear in the figure below.

This plot can be regenerated as follows:
import royalroads as rr rr.GA(rngSeed=1, numGenerations=1000, useClamping=True)
The figure shows that the genetic algorithm once again eliminated lower level missteps before eliminating higher level missteps. Instead of diminishing returns, however, the algorithm yielded accelerating returns as the run proceeded, which is in line with the decision theoretic observation that higher steps are easier to get right than lower steps. By generation 600, the genetic algorithm had found a chromosome with the maximum fitness of 100.
A single generation of the genetic algorithm incurs the same number of fitness evaluations as one period of simulated annealing, allowing us compare the performance of the two algorithms. The figure below shows the mean maximal fitness value per generation/period over forty runs of simulated annealing (in purple) and recombinative evolution (in green). The error bands show one standard deviation above and below the mean.

This plot was generated as follows:
import royalroads as rr rr.compareAlgorithms(numRuns=40)
The mean maximal fitness in the final generation/period of simulated annealing and the genetic algorithm are given below.

The superior performance of recombinative evolution can be attributed to the methodical way it solves the problem.
Deep Hierarchy vs. Deep Contingency
The general results presented in the previous section are predicted by the generative fixation theory of adaptation (Burjorjee 2009, 2013) and the hypomixability theory of recombination. They are not, to the best of my knowledge, predicted by any verificationist theory currently in existence, and they are certainly not predicted by any theory having to do with hierarchical composition. In fact, the provable absence of hierarchical modularity in contingent parity functions, makes these results a good counterexample to hierarchical composition based hypotheses.
With the attention currently being devoted to all things “deep”, the hierarchical composition that purported occurs in recombinative evolutionary systems recently acquired a new name: deep optimization. Just as deep learning composes low level feature detectors into high level feature detectors, so does recombinative evolution, the story goes, compose low level modules into high level modules.
On the one hand I find this new name problematic—dangerous even—because the it promotes hierarchical compositionalism under a catchy new name while papering over the evidence against this class of hypotheses (the efficacy of uniform crossover, for starters). On the other hand, I do like the name because I believe it can help focus attention on the difference between generative fixation and hierarchical composition. While both hypotheses assume fitness functions with “depth”, very different assumptions are made about form this depth takes. Hierarchical composition based hypotheses, of course, assume a deep hierarchy of modules. The generative fixation hypothesis on the other hand makes a much weaker assumption—that of deep contingency: higher level modules owe their existence (or non-existence as the case may be) to the fixation of lower level genes. Unlike hierarchical depth, the existence of a given higher level module is not pre-established.
Conclusion
In this post I have explained how the the promising field of evolutionary computation has been ill-served by a vampirical theory on the one hand (hierarchical composition) and logical positivism on the other. I have argued that the way forward lies in rigorous adherence to the scientific method, a defining characteristic of which is the making and testing of weird predictions. Accordingly I have introduced contingent parities functions, a class of non-trivial, whitebox fitness functions whose structural properties are such that the genetic algorithm can be expected to outperform local search algorithms. On at least one such function, I have demonstrated that a simple genetic algorithm, when augmented by a simple mechanism called clamping, handily outperforms simulated annealing. These results and arguments lend support to the generative fixation theory of adaptation and the hypomixability theory of sex.
The importance of shoring up the foundations of evolutionary computation cannot be overstated. At stake is an understanding of the computational efficiencies at play in recombinative evolution, a final understanding of the computational purpose of sex, and more broadly, an understanding of the place and utility of the scientific method in Computer Science. Then, of course, there are the engineering ramifications of all of the above.
To learn more about generative fixation and the role of recombination in evolutionary systems check out my papers on hyperclimbing and hypomixability. I encourage you to use the theories presented therein to make predictions of your own and to publicize your attempts to validate them—successful and otherwise.
Update: A generalization of the contingent parities problem with multiple independent deeply contingent components is presented, and the performance of a genetic algorithm on an instance of this problem is examined in my next post
References
Burjorjee, K. M. (2009). Generative fixation: a unified explanation for the adaptive capacity of simple recombinative genetic algorithms. Brandeis University.
Burjorjee, K. M. (2013). Explaining optimization in genetic algorithms with uniform crossover. In Proceedings of the twelfth workshop on Foundations of genetic algorithms XII (pp. 37-50). ACM.
Heisenberg, W. (1971). Positivism, Metaphysics and Religion. In Ruth Nanda Nanshen. Werner Heisenberg – Physics and Beyond – Encounters and Conversations. World Perspectives 42. Translator: Arnold J. Pomerans. New York: Harper and Row. p. 213.
Holland, J. H. (2000). Building blocks, cohort genetic algorithms, and hyperplane-defined functions. Evolutionary computation, 8(4), 373-391.
Kuhn, T. S. (2012). The structure of scientific revolutions. University of Chicago press.
Latour, B. (1987). Science in action: How to follow scientists and engineers through society. Harvard university press.
Mitchell, M. (1998). An introduction to genetic algorithms. MIT press.
Nagle, E. and Newman, J.R. (2001). Godel’s Proof, New York University Press.
Popper, K. (2007a). Conjectures and Refutations. Routledge.
Popper, K. (2007b). The Logic Of Scientific Discovery. Routledge.
Vose, M. (1999). The Simple Genetic Algorithm: Foundations and Theory. Cambridge, MA: MIT Press
Watson, R. A. (2006). Compositional evolution: the impact of sex, symbiosis and modularity on the gradualist framework of evolution. MIT Press.

[…] When Will Evolution Outperform Local Search?: https://blog.evorithmics.org/2016/01/31/when-will-evolution-outperform-local-search/ […]
[…] For a Royal Road function on which a genetic algorithm trounces simulated annealing, but not because it behaves as described in the building block hypothesis, see the longer version of this post: When Will Genetic Algorithms Outperform Local Search […]