
Recently, I showed that a simple genetic algorithm with uniform crossover can solve a noisy learning 7-parity problem efficiently—in 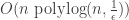

The implicit concurrency hypothesis posits that the efficient learning of relevant variables in the presence of large numbers of irrelevant variables is precisely what gives evolution its power; so, understandably, when I read about the learning juntas problem a few weeks ago (on this blog), I sensed the possibility of a connection. Formally, a 





Observe how this problem abstracts the genetic epidemiology problem mentioned above. The junta are the genetic loci participating in the presence/absence of the disease. The hidden function specifies which configurations of alleles at these loci cause the disease, and which ones do not. The problem of learning the relevant loci is the problem of learning juntas. Also note that the learning juntas problem generalizes the learning parities problem straightforwardly. Whereas the hidden function in the case of learning parities must be the parity function, the hidden function in the case of learning juntas can be any boolean function over the juntas.
Here is an evolution based algorithm, written in Python, that learns juntas given a membership query oracle. And here is a tutorial on its usage. For any value of 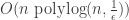
Implications for the Neo-Darwinian Synthesis
It seems like more than a coincidence that
- The Learning Juntas problem abstracts the genetic epidemiology problem mentioned earlier
- Evolutionary computation can efficiently solve the Learning Juntas problem for small numbers of juntas.
One is hard pressed not to hypothesize that evolution takes the form it takes precisely because this form allows it to solve a problem that is similar to the genetic epidemiology problem in all significant ways, save two :
- The problem is to learn the genetic loci participating in fitness/hotness not disease penetrance (often the same loci, but by no means always)
- Unlike computational geneticists, evolution has access to an active oracle.
Given the straightforwardness of this idea it may seem odd that it has not been forthcoming from Evolutionary Biology itself; that is until one realizes that a deep-rooted practice in Population Genetics actively steers theorists away. A vestige from the days before computers, when pen, paper, and mathematics was all one had, the conflation of the unit of inheritance with the unit of selection casts a long shadow. More about this in Sections 2.4.1 and 5.1 of my dissertation.
What now?
Despite the routine use of evolutionary algorithms in science and engineering, computer scientists have been unable to give a straight answer to a simple question: “Is there anything computationally efficient about evolution?” This question can now be answered in the affirmative. Recombinative evolutionary algorithms are capable of efficiently solving a broad, non-trivial problem: Learning
While fascinating from a biological perspective, this answer is not entirely satisfying to the engineer in me because there are conventional algorithms that solve the problem under consideration as efficiently; for example, the binary search algorithm due to Blum and Langley described in Section 5 of the paper by Mossel et al. A more involved algorithm due to Feldman solves the problem almost as efficiently, and does so non-adaptively and in the presence of random persistent classification error.
Have modern ML techniques eclipsed evolution at the very thing it is good at?
I have a hunch that the answer is “no”. It would be fantastic to find generalizations of the learning juntas with membership queries problem that are more difficult for conventional algorithms, but remain efficiently solvable by evolution.
Relevant Computational Learning Theory papers
R.J. Lipton
[web] The Learning Juntas Problem
(An excellent introduction to the Learning Juntas problem)
E. Mossel, R. O’donnell, and R. Servedio
[pdf] Learning Juntas,
(Section 3.1 is especially relevant if you want to reverse engineering the posted Python algorithm)
A. Blum, L. Hellerstein, and N. Littlestone
[pdf] Learning in the Presence of Finitely or Infitely Many Irrelevant Attributes
V. Feldman
[pdf] Attribute-Efficient and Non-adaptive Learning of Parities and DNF Expressions
Relevant papers on Implicit Concurrency
K.M. Burjorjee
[pdf] The Fundamental Learning Problem that Genetic Algorithms with Uniform Crossover Solve Efficiently and Repeatedly as Evolution Proceeds
K.M. Burjorjee
[pdf] Explaining Optimization in Genetic Algorithms with Uniform Crossover
Relevant papers on genetic epidemiology
J.H. Moore, L.W. Hahn, M.D. Ritchie, T.A. Thornton, and B.C. White
[web] Routine Discovery of Complex Genetic Models using Genetic Algorithms
J.H. Moore
[web] The ubiquitous nature of epistasis in determining susceptibility to common human diseases
Last Updated: September 18, 2013
